
NLWeb深度测评:它是下一个SEO,还是另一种炒作?
如果你关注 AI 工具圈,最近可能见过这两个名字:OpenClaw——一个可以把 AI Agent 跑在闲置安卓手机上的开源项目,让普通用户也能拥有 7×24 小时在线的私有 AI 助手。Hermes Agent——我们在用的这个框架,可以浏览网页、调用工具、委托子任务。
这两个东西放在一起,指向一个更大的图景:AI Agent 正在成为互联网的新用户。它们不是通过浏览器看网页,而是直接调用 API。它们不需要点击按钮,直接发请求拿结构化数据。它们不会一个页面一个页面地浏览,而是直接查询它们需要的信息。
这个变化对互联网意味着什么?意味着网站需要从”给人看”变成”给 Agent 读”。你的内容能不能被 AI Agent 发现、理解、调用,决定了你的网站在 AI 时代还有没有存在价值。
这就是 NLWeb 出现的背景。微软说,NLWeb 要成为”AI 时代网站的标准接口”,让你的网站变成一个可以被自然语言查询的 API 端点。R.V. Guha——RSS、RDF、Schema.org 的原作者——亲自操刀这个项目,听起来又是一个互联网基础设施级别的机会。
但我花了一周时间把整个项目翻了个底朝天:从 GitHub 1100 多个 commit 到 Spec v0.55 协议规范,从微软 Build 大会发布视频到实际部署踩坑的开发者博客,从 WordPress 生态现状到与几位一线工程师的深度讨论。
结论写在前头:对大多数内容型网站来说,NLWeb 的完整实现是一个投入产出比极差的工程,绕一圈回来,最有价值的部分还是 Schema.org。
这篇文章把 NLWeb 从里到外说清楚,包括它在整个协议栈里的位置、真实的技术实现路径、电商和内容网站的分化,以及你的网站真正该做的唯一一件事。
一、NLWeb 是什么
一句话定义
NLWeb(Natural Language Web)是微软 2025 年 5 月在 Build 开发者大会上推出的开源项目,核心目标只有一个:让任何网站都能用自然语言被人类和 AI Agent 查询,把你的网站变成一个 AI 可对话的 API 端点。发起人是 R.V. Guha——RSS、RDF、Schema.org 三个标准的主要创建者,三大标准全部出自他手。
典型使用场景
传统模式:用户去搜索引擎,搜”北京适合带孩子去的餐厅”,看排名,点击链接,进入餐厅官网,浏览菜单,判断是否合适。
NLWeb 模式:用户对 AI 助手说”帮我找北京适合带孩子去的餐厅,要有室外座位”,AI 直接查询接入了 NLWeb 的餐厅网站(或者调用 Tripadvisor 的 NLWeb 端点),拿回结构化数据,生成推荐,用户在 AI 里就完成了决策,不需要点击任何链接。
这背后的转变是:从”网站被访问”到”网站被查询”。
两个核心端点
/ask:REST API,自然语言查询入口,人类和 Agent 都能调用。发一个问题过去,拿回 Schema.org 格式的结构化 JSON。
/mcp:MCP(Model Context Protocol)端点。你的网站自动成为一个 MCP Server,Claude Desktop、VS Code Copilot、Cursor——整个 MCP 生态里的任何 AI 工具,都能直接调你的网站,不需要任何人工配置。
这是 NLWeb 最被低估的价值:一次部署,同时服务人类对话和程序化 Agent 查询。
二、NLWeb 在整个协议栈里的位置
说清楚 NLWeb,需要先说清楚它旁边还有哪些协议。AI Agent 的世界正在快速标准化,出现了四层协议,它们解决不同层次的问题,是互补关系,不是竞争关系。
第一层:MCP(Model Context Protocol)
Anthropic 在 2024 年 11 月推出,2025 年 3 月 OpenAI 跟进,4 月 Google 确认支持,5 月微软加入 steering committee,7 月 VS Code 支持达到 GA。
核心解决的问题:AI 应用如何连接外部工具和数据源。类比是”USB-C”——有了统一标准,MacBook 可以接任意 USB-C 设备,不需要为每个设备写专门驱动。
第二层:A2A(Agent to Agent Protocol)
Google 在 2025 年 4 月推出,6 月捐赠给 Linux Foundation,成员包括 Salesforce、SAP、ServiceNow、PayPal、Atlassian、微软、AWS。
核心解决的问题:不同厂商的 AI Agent 如何相互发现、委托任务、协调行动。
典型场景:用户找客服 Agent 说”我要退款”,Agent 判断需要转给billing Agent,billing Agent 判断需要再调 payments Agent——三个不同厂商的 Agent 通过 A2A 协议协作,用户看到的是一个无缝交互。
Agent 之间通过”Agent Card”(/.well-known/agent-card.json)相互发现,每个 Agent 声明自己有什么能力、需要什么认证。
第三层:NLWeb(Natural Language Web)
微软 2025 年 5 月推出。核心解决的问题:网站内容如何被自然语言查询。
类比:”NLWeb is to MCP/A2A what HTML is to HTTP。”
HTML 让任何人都能建网站,HTTP 让浏览器和服务器能对话。NLWeb 让任何网站都能用自然语言被查询,MCP/A2A 让查询结果能在 Agent 之间流转。
第四层:AGENTS.md
给 AI 编码者的指令说明,让 AI 在处理代码仓库时能正确理解项目结构和上下文。
UCP 和 ACP 是另一条线
Shopify 和 Google 在 2026 年 1 月推出 UCP(Universal Commerce Protocol),Stripe 和 OpenAI 在 2025 年 9 月推出 ACP(Agentic Commerce Protocol)。这两是垂直领域的商务协议——解决 AI 如何完成交易、支付、结账。
NLWeb 管内容查询发现,UCP/ACP 管交易支付。两者互补,不是竞争关系。Shopify 同时支持 NLWeb(内容)+ UCP(商务),分工明确。
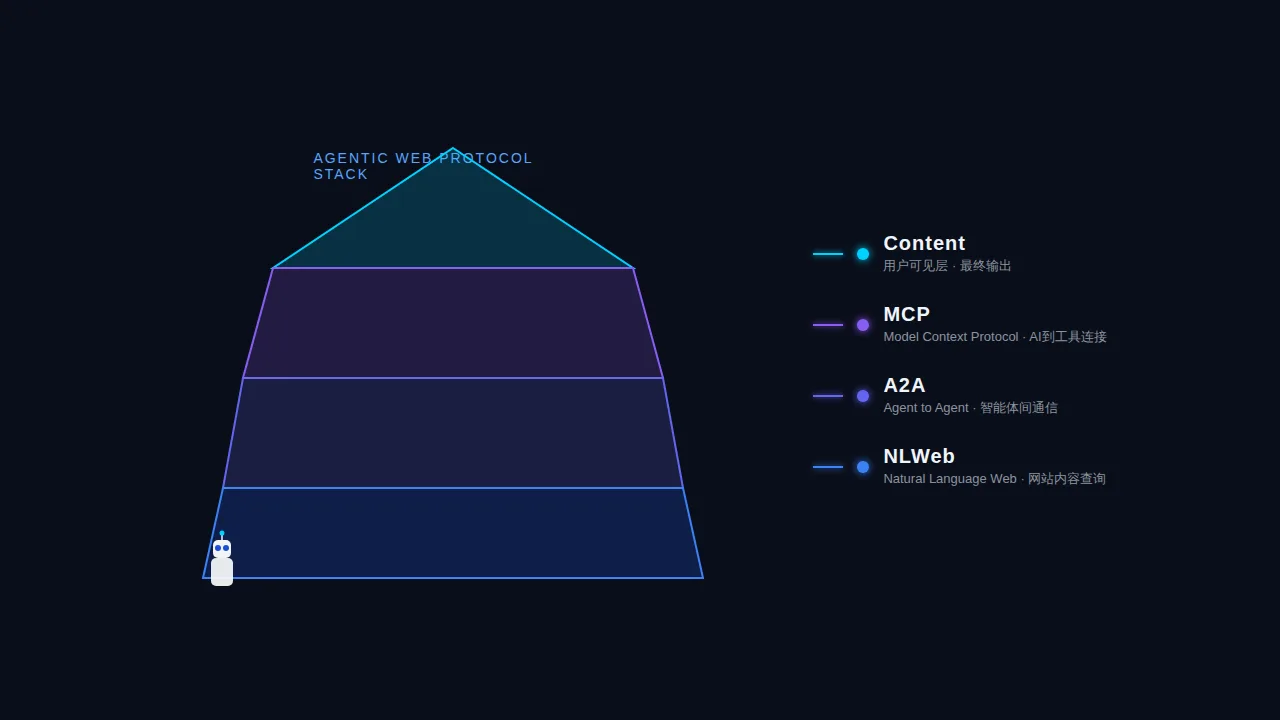
NLWeb 协议栈金字塔
治理:行业在协作,不是碎片化竞争
2025 年 12 月,MCP 和 A2A 一起被捐赠给 Linux Foundation 旗下的 Agentic AI Foundation(AAIF)。成员名单:AWS、Anthropic、Block、Bloomberg、Cloudflare、Google、Microsoft、OpenAI。
这是史上第一次,这些公司在同一个基金会上合作。Jim Zemlin(Linux Foundation 执行董事)说:”我们看到 AI 正在进入一个新阶段,从对话系统转向自主 Agent,它们需要协同工作。”这不是客气话,是实际行动。
三、技术架构详解
数据管道:三步走
第一步,数据接入:NLWeb 的爬虫从网站提取 Schema.org JSON-LD 标记。如果你的网站用 JSON-LD 做 SEO 标记,这一步最直接。RSS feed 也能被自动转换成 Schema.org 类型。
第二步,语义存储:提取的 Schema.org 数据被存入向量数据库。这一步是后面所有问题的根源,后面展开说。
第三步,自然语言查询:用户提问,LLM 结合向量检索结果 + Schema.org 语义层 + 外部知识,生成自然语言答案。
查询处理:50+ 路并行 LLM 调用
NLWeb 的查询处理不是用一个超大 Prompt 一次处理,而是分解为 50 多个小而具体的任务并行跑:相关性检查、去语境化、记忆检测、快速通道……每个任务一个专门的 LLM 调用。
这样做的好处:质量更高,可解释性更强,错误能定位到具体哪一步。坏处是每次查询成本翻倍。NLWeb 的 README 里专门提到了这个设计选择,说是”specialists outperform generalists for specific tasks”。
请求和响应结构(Spec v0.55)
一个 NLWeb /ask 请求长这样:
{
"query": {
"text": "protein rich recipes with cinnamon",
"site": "pumpkins-r-us.com",
"location": "Idaho",
"price": "less than $20"
},
"context": {
"prev": ["breakfast muffins", "high fiber snacks"],
"memory": "vegetarian, has a sweet tooth"
},
"prefer": {
"mode": "list, summarize",
"streaming": false
},
"meta": {
"version": "0.55",
"session_context": { "conversation_id": "conv_98765" }
}
}响应是 Schema.org 格式的 JSON:
{
"_meta": {
"response_type": "answer",
"response_format": "conversational_search",
"version": "0.55"
},
"results": [
{
"@type": "Recipe",
"name": "Pumpkin spice with coconut",
"cookTime": "PT30M",
"grounding": { "sourceURL": "https://..." },
"actions": [{ "@type": "AddToCartAction" }]
}
]
}三种响应模式:list(返回排序结果)、summarize(摘要)、generate(RAG 风格直接生成答案)。
四、向量数据库:三层失真的叠加
这是 NLWeb 最核心的问题,也是大多数介绍文章不愿意直说的地方。NLWeb 的数据管道,向量数据库是必经之路。这一步是所有麻烦的根源。
第一层失真:向量化本身就是压缩
把一段自然语言文本转换成几百维的向量,是有损压缩。语义相近的段落可能向量相近,但”相近”不等于”相同”。一个细微的观点转折、一个条件限定、一个态度反转——这些在向量空间里可能完全被抹平。
第二层失真:相似度匹配不等于相关性
向量检索的本质是找”最接近”的向量,但最接近不等于最相关。
举一个具体例子:一个卖奢华皮革手机套的网站,用户搜”轻奢手机配件”。向量检索会找到和”手机配件”最接近的内容,而不是和”轻奢”最相关的内容。如果竞品是走性价比路线的,他们的产品页面可能有更多”手机配件”这个关键词出现,向量空间里反而更近。
这就是向量检索的死穴:语义覆盖不等于语义匹配。
第三层失真:LLM 综合放大误差
前两层的误差在 LLM 生成答案时被叠加放大。RAG 的幻觉问题——很多人以为是 LLM 本身的能力问题——实际上根源在向量检索精度不足。这是几位在实际项目里踩过这个坑的一线工程师告诉我的。
三层累积下来,内容型网站(文章、教程、深度分析)受损最重,因为这类内容的语义关系复杂,向量化的损失是实质性的。
电商和旅行网站对这个架构接受度更高:产品属性标准化,用户查询意图明确(”带室外座位的餐厅”),向量失真问题不严重。所以 NLWeb 的早期采用者里有 Eventbrite 和 Tripadvisor,但没有内容型网站。
结论:回源比过向量层更可靠。让 AI 直接读原始数据,不要经过向量转换。NLWeb 的架构绕不开向量数据库,这是它对内容网站不友好的根本原因。
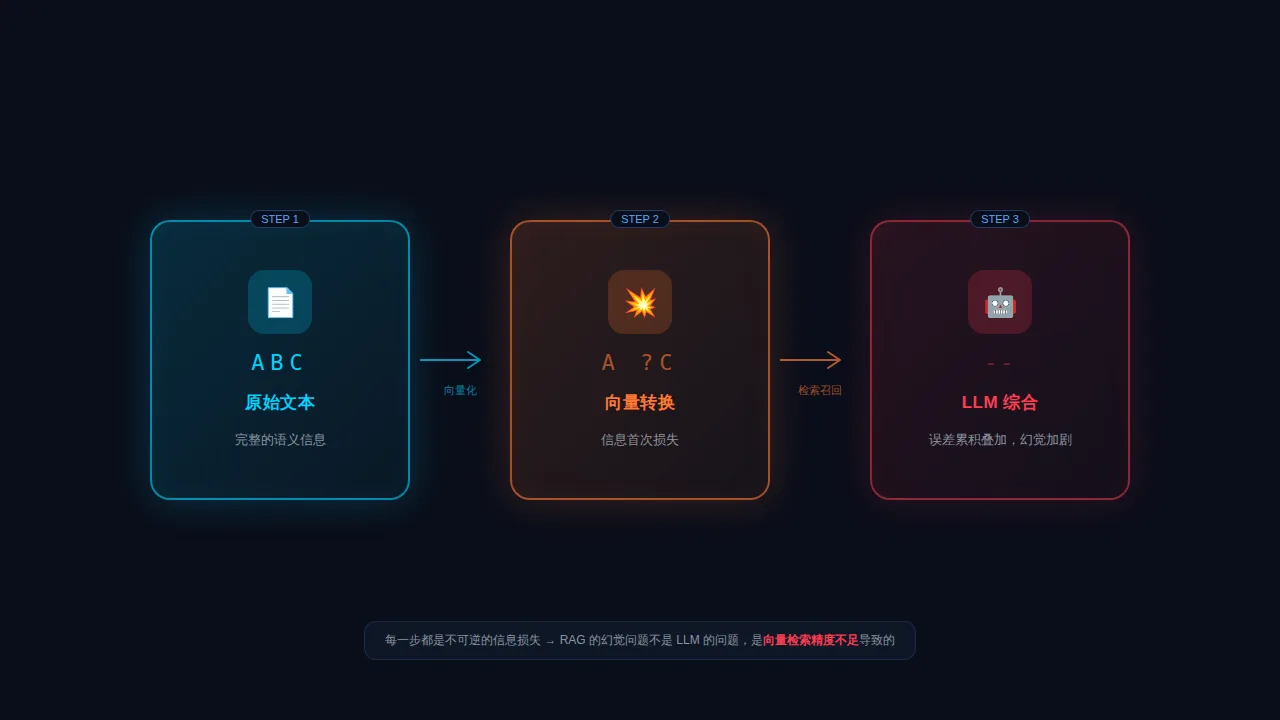
向量数据库三层失真链
五、WordPress 的三条接入路径
NLWeb 不是”装上就完事”,需要额外部署服务层。以下是三条可行路径,从简单到复杂。
路径一:Yoast + NLWeb(最干净,但需等待)
WordPress + Yoast SEO Premium 的用户,Yoast 正在推进 NLWeb 集成。Yoast 的 Schema Aggregation 功能把你的全站 Schema 聚合成本地图谱,NLWeb 直接从这个图谱读取数据,不需要额外爬虫。
但:Yoast 帮你整理 Schema 数据,向量数据库和 NLWeb 服务层仍然要自己部署。Yoast 只是数据层的集成,不是完整方案。
路径二:nlweb-wp 插件(轻量,即插即用)
这个社区插件做了两件事:生成符合 NLWeb 协议的 RSS Feed(Schema.org 格式),前端注入 Chatbot 对话界面。
数据流:WordPress REST API → 插件生成带 Schema.org 元数据的 RSS → NLWeb /ask 端点读 RSS
优点:不需要向量数据库,实现成本低。缺点:功能基础,依赖 WordPress REST API,适合小规模站点。
路径三:官方 NLWeb 参考实现(生产级,最复杂)

爬虫定时跑,数据写入向量库,需要维护整套基础设施。适合有工程资源、有持续更新需求的大型站点。
六、Schema.org 做好了,不需要 NLWeb 也能被 AI 找到
这是整篇文章最反直觉的部分,也是大多数从业者不愿意说的部分。
Schema.org 标记做好了,Google AI Overview 能引用你,Perplexity 能抓你,ChatGPT 实时搜索能索引你——这些是免费的、已经存在的流量入口,不需要跑任何 NLWeb 服务。
AI 搜索的底层逻辑:检索层找到相关内容,匹配层判断内容是否真的回答了问题。你的 Schema.org 标记完整、准确、结构化,AI 就能正确理解你的内容。
AI 的检索来源不是只有 NLWeb。Google 的 AI Overviews 主要依赖传统搜索引擎索引+Schema.org 信号;Perplexity 的抓取逻辑和主流搜索引擎兼容;ChatGPT 的实时搜索也是类似逻辑。Schema.org 做好,这些渠道都能覆盖。
NLWeb 的真正价值只在这两个场景成立:
第一,标准化接口。NLWeb 让 AI Agent 能自动发现”这个网站支持自然语言查询”,不需要人工配置。这是 MCP 生态里的自动发现机制,是真实价值。但前提是你已经部署了完整服务层。
第二,Shopify 这类电商平台。产品目录天然结构化,用户查询意图明确,向量失真问题不严重,NLWeb 的投入产出比是合理的。
对内容型网站,两个价值都不成立。
七、NLWeb 的真实价值重估
| 宣传价值 | 实际情况 |
|---|---|
| 零成本接入 | 向量数据库+服务层仍需自建 |
| Schema.org 零成本复用 | 仅限 WordPress + Yoast 用户 |
| 所有网站都适合 | 仅对结构化数据充足的电商/旅行网站有意义 |
| AI 流量入口 | 内容型网站投入产出比极差 |
| 主流 LLM 都会支持 | 协议层已定,但 AI 平台是否优先支持仍不确定 |
NLWeb 这个名字起得很好,蹭了”自然语言”的热度,听起来像是要让你的网站开口说话。但它本质上是一个数据协议,不是内容优化工具。真正让你的内容被 AI 正确引用的,不是部署什么协议,是 Schema.org 标记的质量。
这件事做好了,AI 能不能找到你已经不取决于有没有 NLWeb。这件事做不好,上了 NLWeb 也只是让 AI 更高效地引用你的错误信息。
八、谁真正需要 NLWeb
说了这么多,NLWeb 有用吗?有。在以下场景里,投入是值得的:
电商产品目录:产品属性标准化,查询意图明确,Schema.org 标记基础好。Shopify 已经集成 NLWeb,商家接入成本相对低。
旅行/餐饮平台:Tripadvisor、Eventbrite 这类早期采用者已经验证了场景可行性。结构化数据充足,NLWeb 的 /ask 端点能直接返回用户需要的实体信息。
有专属 Agent 生态的企业:如果你有自己的 Agent 生态需要和外部网站交互,NLWeb 的 MCP 端点是标准化程度最高的对接方案。
愿意投入工程资源的团队:向量数据库和服务层的维护成本是真实的,但如果团队有能力、有意愿投入,这套架构是可用的。
九、你的网站现在该做什么
一件事:审核 Schema.org 标记质量。
这不是唱衰 NLWeb。NLWeb 的方向是对的,R.V. Guha 的判断值得尊重。但在基础设施还不成熟的阶段,对大多数内容型网站而言,Schema.org 审计是 ROI 最高的投入,没有之一。
第一,审核 JSON-LD 完整性。检查你的主要页面类型是否包含完整属性:文章需要 Article Schema(headline、author、datePublished、image);产品需要 Product Schema 加 Offer Schema(price、availability、seller);本地商家需要 LocalBusiness Schema(address、openingHours、geo)。
第二,检查 entity 关系准确性。Schema Graph 里的 entity 关系是否正确对应页面实际内容?作者 entity 是否正确链接到作者页面?产品 entity 的品牌、类别、评价是否和实际一致?
第三,确保实时数据同步。库存、价格、评分这些实时变化的属性,是否有机制保持 Schema 标记和页面实际内容同步?过时或不准确的 Schema 标记比没有更危险——AI 会优先引用结构化数据,错了就会被更高效地传播。
没有 Schema.org 基础,上任何协议都是空中楼阁。有了扎实的 Schema.org 投入,NLWeb 的价值才值得被考虑——而且只有在你有真实的内容查询需求时。
结语
NLWeb 是一个被高估了的技术叙事,和一个被低估了的数据标准。
它被高估的地方:作为一个完整的端到端解决方案,对内容型网站来说太复杂、太贵、太绕。
它被低估的地方:它再次证明了 Schema.org 数据质量是 AI 时代最值得投入的资产,这件事做好了,AI 能不能找到你已经不取决于有没有 NLWeb。
方向是对的,时机还没到。对大多数内容网站,现在该做的只有一件事,Schema Markup。





